Challenging Nomad: TiānshūBench Experimental Release 0.0.Y

Greetings cosmic calligraphers, and welcome to the TiānshūBench version 0.0.Y benchmark, for July 2025.
Since the last update, I've added a few new features:
-
Using Nvidia NIM in addition to Chutes.ai, which means
- results for more models
-
Cleaned up tests with better error handling, etc.
Nvidia NIM was a very great to find, because it is yet another free service that allows testing against various open-weight models. For instance, it let me test Llama-4 Maverick, which never worked right for me in Chutes. Also, it let me check multiple implementations of the same model to verify that the results I was getting were correct.
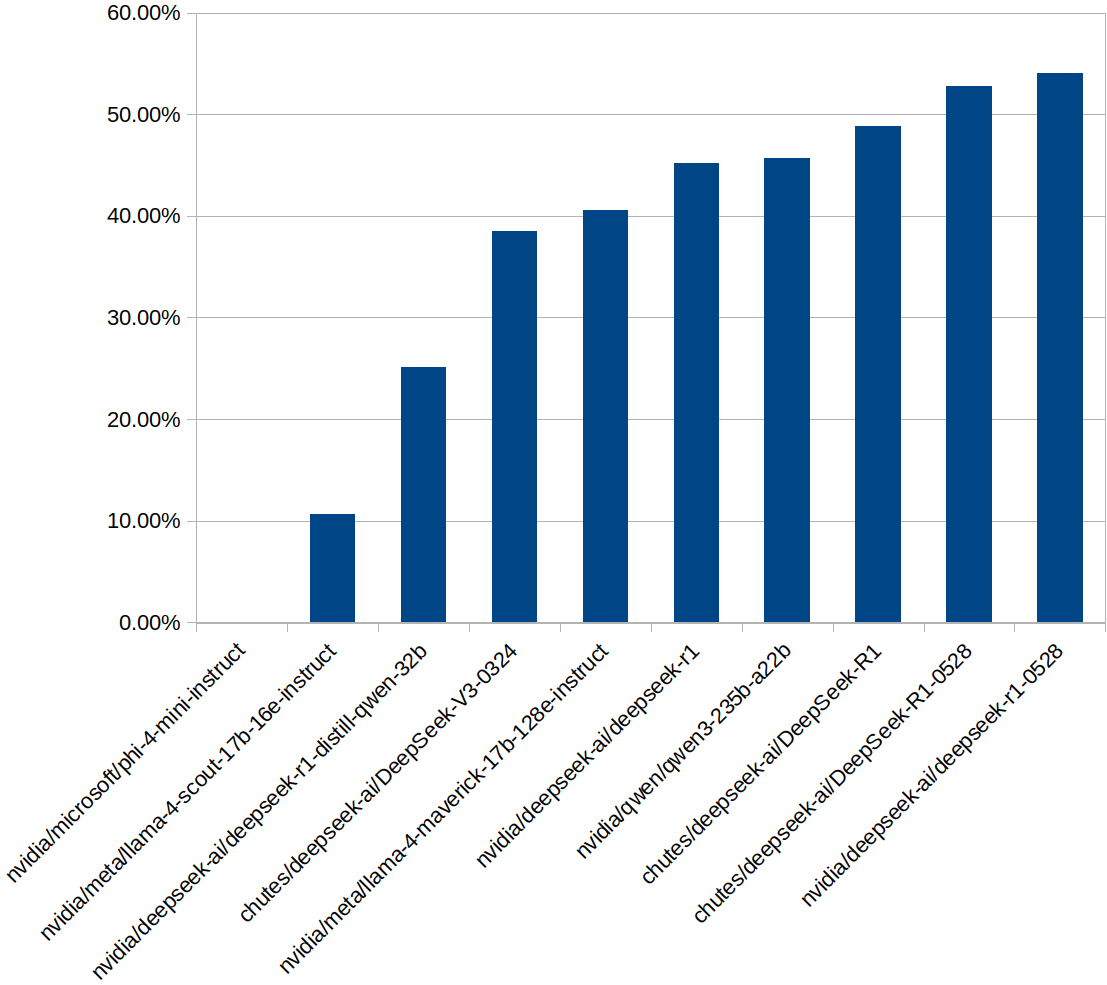
=== Statistics by Model ===
chutes/deepseek-ai/DeepSeek-R1: 306/627 (48.8%) passed, 321 failed, 13 skipped, 640 total
chutes/deepseek-ai/DeepSeek-R1-0528: 335/635 (52.76%) passed, 300 failed, 5 skipped, 640 total
chutes/deepseek-ai/DeepSeek-V3-0324: 244/633 (38.55%) passed, 389 failed, 7 skipped, 640 total
nvidia/deepseek-ai/deepseek-r1: 268/593 (45.19%) passed, 325 failed, 47 skipped, 640 total
nvidia/deepseek-ai/deepseek-r1-0528: 316/585 (54.02%) passed, 269 failed, 55 skipped, 640 total
nvidia/deepseek-ai/deepseek-r1-distill-qwen-32b: 127/505 (25.15%) passed, 378 failed, 135 skipped, 640 total
nvidia/meta/llama-4-maverick-17b-128e-instruct: 256/631 (40.57%) passed, 375 failed, 9 skipped, 640 total
nvidia/meta/llama-4-scout-17b-16e-instruct: 68/638 (10.66%) passed, 570 failed, 2 skipped, 640 total
nvidia/microsoft/phi-4-mini-instruct: 0/291 (0.0%) passed, 291 failed, 349 skipped, 640 total
nvidia/qwen/qwen3-235b-a22b: 290/634 (45.74%) passed, 344 failed, 6 skipped, 640 total
I am worried about the “skipped” results. Digging into the logs, it's mostly due to what looks like read timeouts or network errors. This is tough to get around, as the code already makes multiple retries on network failures, and these failures mean that we weren't getting results, even after backing off and retrying several times over the course of 15 minutes.
I'm also a bit worried over the results from Microsoft Phi. 0% passed! How can that be?
Some of Phi's responses, however, are genuine garbage results:
Sure, 1, and then, a, a, a, and, and, and, and, and, and, and, and, and, and, and, and, and, and,
*. 1,
* 1, and, and, and, and, and, 1, are, and, and. 1, 1, and, and, and, and, and, and, and, and, and, and, and, and, and, and,, and,,1,1,, 1,1,1, and, and,1,1. 1. 1. 1,, 1, and,1,,1, and, and, and,1, and,1,1, and, and, and, and, and, and, and,1, and,1, and,,,,,,,1,1, and,1,1,1,1,1,1,1,1
1,1,1,,,,,,,,1,,1,1, 1,1,1,1,1,1,1,1,1,1,1.
This reminded me of the time Captain Kirk talked the AI-powered space probe Nomad into blowing itself up.
Phi also gets confused at the TiānshūBench language requirement that each statement end with a semicolon. I noticed that the language documentation doesn't explicitly call this out, and, in fact, there's a “Hello World” type example in the documentation that skips ending the statement with a semicolon. I'll tighten this up on the next go around.
Of course, increasing test time compute with a more agentic approach and allowing retries lets the models succeed much more:
=== Statistics by Number of Shots ===
1 shots: 329/1449 (22.71%) passed, 1120 failed, 151 skipped, 1600 total
2 shots: 431/1510 (28.54%) passed, 1079 failed, 90 skipped, 1600 total
4 shots: 634/1403 (45.19%) passed, 769 failed, 197 skipped, 1600 total
8 shots: 816/1410 (57.87%) passed, 594 failed, 190 skipped, 1600 total
That's all for now. I think next up is to test some more models, perhaps even some of the paid ones!
Comments