But Can It Think? A Quick Look at Kimi K2

The Internet's been abuzz with talk of Kimi K2, the latest open-weight LLM out of Moonshot AI. Word on the street is that it can go head-to-head with the latest frontier models. But how does it stack up on the TiānshūBench test of fluid intelligence, coding, and reasoning?
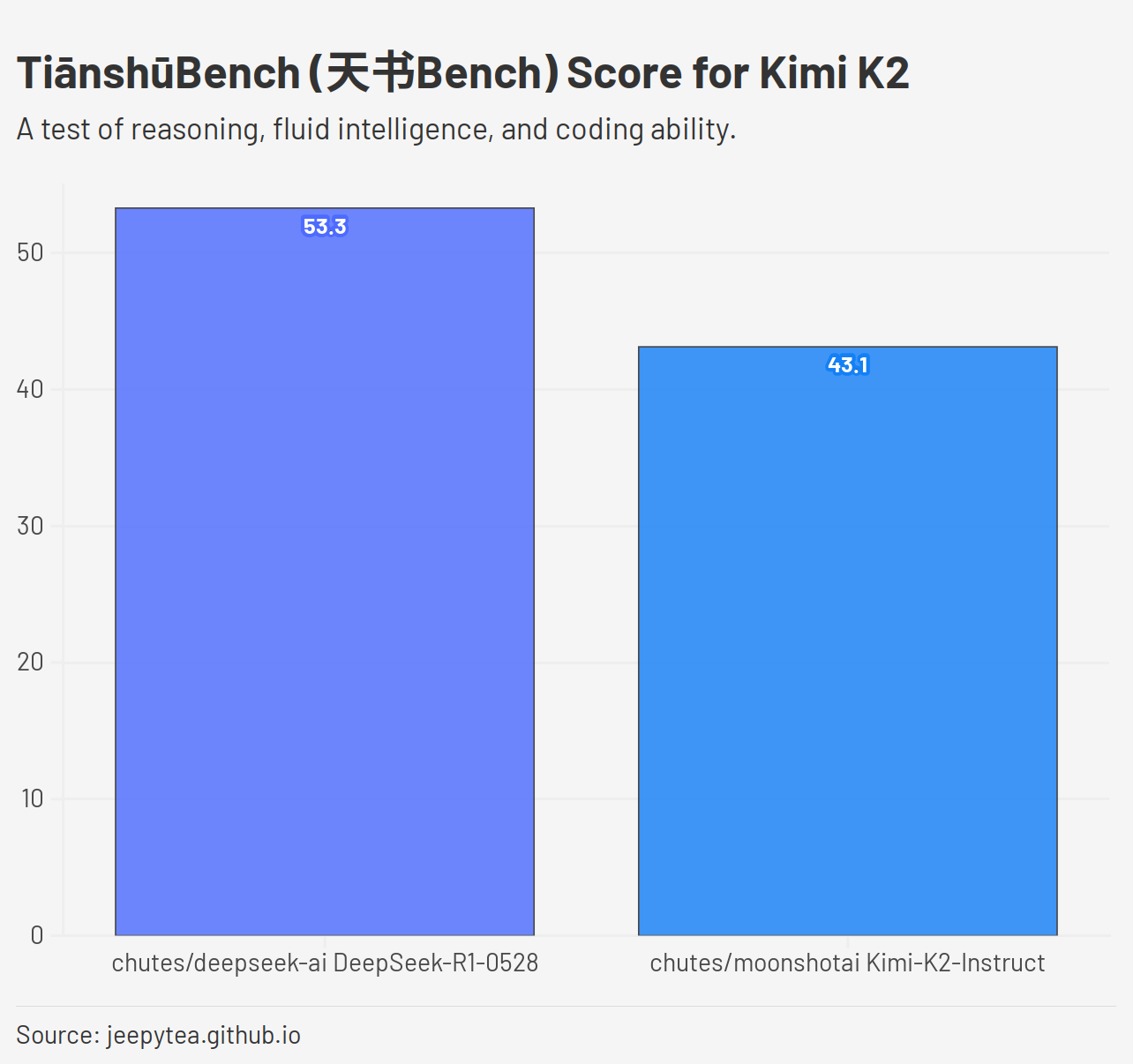
Not as good as we expected! Kimi K2 scores a 43.1 vs. DeepSeek R1 0528's score of 53.3 in the latest experimental version of TiānshūBench.
TiānshūBench Progress: Updates to the Benchmark
In the latest test runs, some of the easier tests are well into the saturated range, and will probably be excluded from future scores. We'll also be adding a few more tests in the “hard” range.
=== Statistics by Test Case For All Models ===
test_case0: 83.64% passed
test_case1: 90.18% passed
test_case2: 86.61% passed
test_case3: 97.5% passed
test_case4: 95.65% passed
test_case5: 32.71% passed
test_case6: 34.23% passed
test_case7: 49.52% passed
test_case8: 17.05% passed
test_case9: 21.84% passed
test_case10: 17.07% passed
test_case11: 17.44% passed
test_case12: 22.09% passed
test_case13: 28.05% passed
test_case14: 17.98% passed
test_case15: 27.71% passed
=== Statistics by Problem For All Models ===
001: Extract Odd Digits: 86.83%
002: Print String: 97.5%
003: Echo String: 95.65%
004: Test string: 38.7%
005: Integer counting: 18.37%
006: Delimiter matching: 23.82%
Also of note on this most recent run is that the free Nvidia API is not very reliable. It kept timing out when making calls to the DeepSeek-R1 endpoint. Chutes is better but still unreliable, and they've started charging for more models. I may seek out faster LLM providers to help make the development loop go much faster.
Comments