Greetings, celestial scribes! When we last left
off,
we were looking at how TiānshūBench
(天书Bench) could
test reasoning, fluid intelligence, and coding ability in LLMs by
dynamically generating programming languages and challenging the LLM
system to solve simple problems using those new programming languages.
Since that time, I've added:
- New tests
- The ability to test against LLM providers
Chutes and Sambanova
- The ability to run the tests in parallel
- Retries in case of network errors
- Enhanced reporting and logging
- Multi-shot testing
Much of the code for the latest version of TiānshūBench was created with
the help of aider, backed by Google
Gemini and Anthropic
Claude.
Trials and Tribulations
One big shift in this benchmark release is the change to using Chutes as
the model inference provider instead of a local
ollama instance as before. The big challenge in
using ollama, as I found out, was that when you demand a model's full
context length from ollama, it becomes EXTREMELY SLOW, to the point of
complete unusability. Long context is critical for the multi-shot tests,
because the context has to include previous failures, in addition to the
somewhat lengthy language description.
In the meantime, I've switched to Chutes as an inference provider as
- It provides a nice selection of models, including some of the top
open-weight models.
- It's free to use once you sign up.
Free to use is extremely important, because, as we'll see, a lot of the
tests didn't work right the first time through (my fault). I would hate
to spend hundreds or thousands of dollars in inference costs, only to
find, for example, that I had mislabeled one of the tests, causing it to
fail every time because the poor LLM had no chance to get it right from
the beginning.
For a free service, it's shockingly reliable, and they only gripe about
my usage when I'm hitting their API really hard. Their servers will
respond with a 429 (Too Many Requests). TiānshūBench will now back off
for a random length of time and try again in case of this or other
network errors.
Like all stuff that's good and free, I don't expect it to last
forever.
If you've got some free LLM usage credits to throw at an independent
researcher, perhaps to prove that YOUR model is the world leader in
TiānshūBench, hit me up.
I'm also contemplating switching back to local models with VLLM or a
similar system, which I understand handles long context better.
Model Madness
In addition to the DeepSeek-R1 and -V3 models, Chutes also offers free
API access to Qwen, GLM, Llama, and the hybrid DeepSeek-R1-0528-Qwen3-8B
models. Unfortunately, these models are not included in this report,
because they either:
- Came back with blank responses once the instructions got too long.
- Started taking way too long to respond on multi-shot tests.
I've got some idea what needs to happen in some of these cases. We need
to separate scoring out by number of shots for one thing. Also, I need
to mess with the temperature and other request parameters to find a
combination that each model likes.
Problematic Parameters
While testing, I noticed that certain test cases were failing nearly
99+% of the time. This would normally be good, because it means that
we've discovered an endeavor that the LLMs aren't really good at yet.
However, upon further inspection, I discovered that my test data just
wasn't set up correctly. For example:
- One set of input and output values was marked with the wrong problem
definition ID.
- Another set of expected output values had a trailing space, causing
all output string comparisons to fail.
The latter case led to 99% failures for that test. There was a bit of
cleverness from DeepSeek-R1-0528 on one run, though. A couple shots into
the run, it managed to pass the test, by figuring out that the test was
wrong.
So the test should now expect "mayd" without space?
But the error message said it expected 'mayd ' (with a space).
This discrepancy might be because the test case has a trailing space
in the expected output?
But the problem says no delimiters.
We are outputting without any space.
Therefore, if the test expects a space, then the test is flawed.
It then went on to produce a program that passed the test. This is
definitely one case where the LLM was smarter than the experimenter.
Precious Parallelism
Rather than coming up with my own testing framework, I decided to build
TiānshūBench around pytest, a unit
testing package for Python code. This has paid off in spades, as pytest
is quite mature and features a number of great plugins for working with
tests.
For instance: for this benchmark report, we're running 3 LLMs X 10
synthetic test languages X 16 test cases X 4 multishot levels, for a
total of 1920 tests. If I had to run these tests one at a time, it would
take over two and a half days to complete the whole suite. This is where
the pytest-xdist plugin comes
to the rescue, as it allows you to easily run any number of tests in
parallel. The command I used to run the test suite is
python -m pytest -svv -n 200 --dist worksteal --report-log=results/report-log-(date –iso=minutes).json --alluredir=results/allure tianshu_bench/benchmarks/test_llm_ability.py::test_execute_generated_multi_shot -k "chutes/ and DeepSeek"
Run this way, the tests run in 200 simultaneous processes, which means
that the suite completes in about 2 hours.
Mystery Tests
Some tests still don't complete when being run this way. I suspect that
it has something to do with pytest-xdist. Anyway, I was able to whip up
a script that figures out which tests didn't run, and re-run those to
output the missing tests' identifiers.
python scripts/find_missing_tests.py results/report-log-2025-06-05T21:52-04:00.json \
--output-missing missing-tests.txt --filter "chutes/ and DeepSeek" \
--test-path "tianshu_bench/benchmarks/test_llm_ability.py::test_execute_generated_multi_shot"
The missing tests can then be re-run with the command above, but
specifying the individual tests.
python -m pytest -svv -n 10 --dist worksteal \
--report-log=results/report-log-(date --iso=minutes).json \
--alluredir=results/allure (cat missing-tests.txt)
Alluring Activity
Another great plugin for pytest is
allure-pytest, for allowing
pytest to work with the Allure reporting
system. This allows a TiānshūBench user to search, sort, and filter
individual tests, and see their results.
Allure allows you to attach files to an individual test, and I use this
functionality to attach a log of the complete conversation with the LLM
during a test. This was how I was able to quickly and mostly painlessly
diagnose problems with the test data, including the issues mentioned
above.
Rolling It Up
To get the benchmark stats, we run the analysis script thusly:
python scripts/analyze_multishot_report.py results/report-log-2025-06-05.json
Statistics by Number of Shots
1 shots: 121/480 (25.21%) passed, 359 failed, 0 skipped, 480 total
2 shots: 155/480 (32.29%) passed, 325 failed, 0 skipped, 480 total
4 shots: 233/480 (48.54%) passed, 247 failed, 0 skipped, 480 total
8 shots: 285/480 (59.38%) passed, 195 failed, 0 skipped, 480 total
Unsurprisingly, the more chances an LLM gets to come up with an answer,
plus some guidance as to what went wrong, the more likely the LLM is to
come up with a correct solution. The trick here in the future will be to
find the LLM that gives the most correct answers for the amount of money
or time that you're spending on inference.
Statistics by Language Seed
Seed 1: 85/192 (44.27%) passed
Seed 2: 80/192 (41.67%) passed
Seed 3: 92/192 (47.92%) passed
Seed 4: 68/192 (35.42%) passed
Seed 5: 85/192 (44.27%) passed
Seed 6: 74/192 (38.54%) passed
Seed 7: 71/192 (36.98%) passed
Seed 8: 74/192 (38.54%) passed
Seed 9: 77/192 (40.1%) passed
Seed 10: 88/192 (45.83%) passed
These represent the different programming languages generated by
TiānshūBench for testing the LLMs. Every test gets every test case in
each of these languages. As expected, there's not a big variation here
in the results, as the languages only differ by their nonsense keywords.
Statistics by Test Case
test_case0: 99/120 (82.5%) passed
test_case1: 100/120 (83.33%) passed
test_case2: 93/120 (77.5%) passed
test_case3: 113/120 (94.17%) passed
test_case4: 107/120 (89.17%) passed
test_case5: 36/120 (30.0%) passed
test_case6: 39/120 (32.5%) passed
test_case7: 34/120 (28.33%) passed
test_case8: 18/120 (15.0%) passed
test_case9: 16/120 (13.33%) passed
test_case10: 14/120 (11.67%) passed
test_case11: 26/120 (21.67%) passed
test_case12: 27/120 (22.5%) passed
test_case13: 19/120 (15.83%) passed
test_case14: 34/120 (28.33%) passed
test_case15: 19/120 (15.83%) passed
001: Extract Odd Digits: 292/360 (81.11%) passed
002: Print String: 113/120 (94.17%) passed
003: Echo String: 107/120 (89.17%) passed
004: Test string: 109/360 (30.28%) passed
005: Integer counting: 74/480 (15.42%) passed
006: Delimiter matching: 99/480 (20.62%) passed
Test_case_10, the most-failed test case, is a fairly simple task that
requires a loop and a conditional. It's a test involving problem ID
005:
Write a program in Possions that does the following:
Reads a string from standard input.
If that string represents a single digit integer, with no other characters, the program should:
output the integer, and all of the greater integers up to 10 inclusive, with a space between each integer.
So for input "5", output should be "5 6 7 8 9 10" with no quotes.
If the input is not a single digit integer, output "None" with no quotes.
And here's a solution from DeepSeek-R1-0528:
input = ask("");
valid = 0;
ripted (len(input) == 1) {
ripted (input su "0123456789") {
valid = 1;
}
}
ripted (valid == 1) {
n = int(input);
result = "";
sohanidd i su n -> 10 {
ripted (result != "") {
result = result + " ";
}
result = result + str(i);
}
miciously(result);
}
ripted (valid == 0) {
miciously("None");
}
But most LLMs seem to get tripped up on the syntax for this problem.
There need to be many more of these test cases and they need to be much
harder if we are to avoid benchmark saturation. Perhaps following the
example of test_case_10 can give us some guidance.
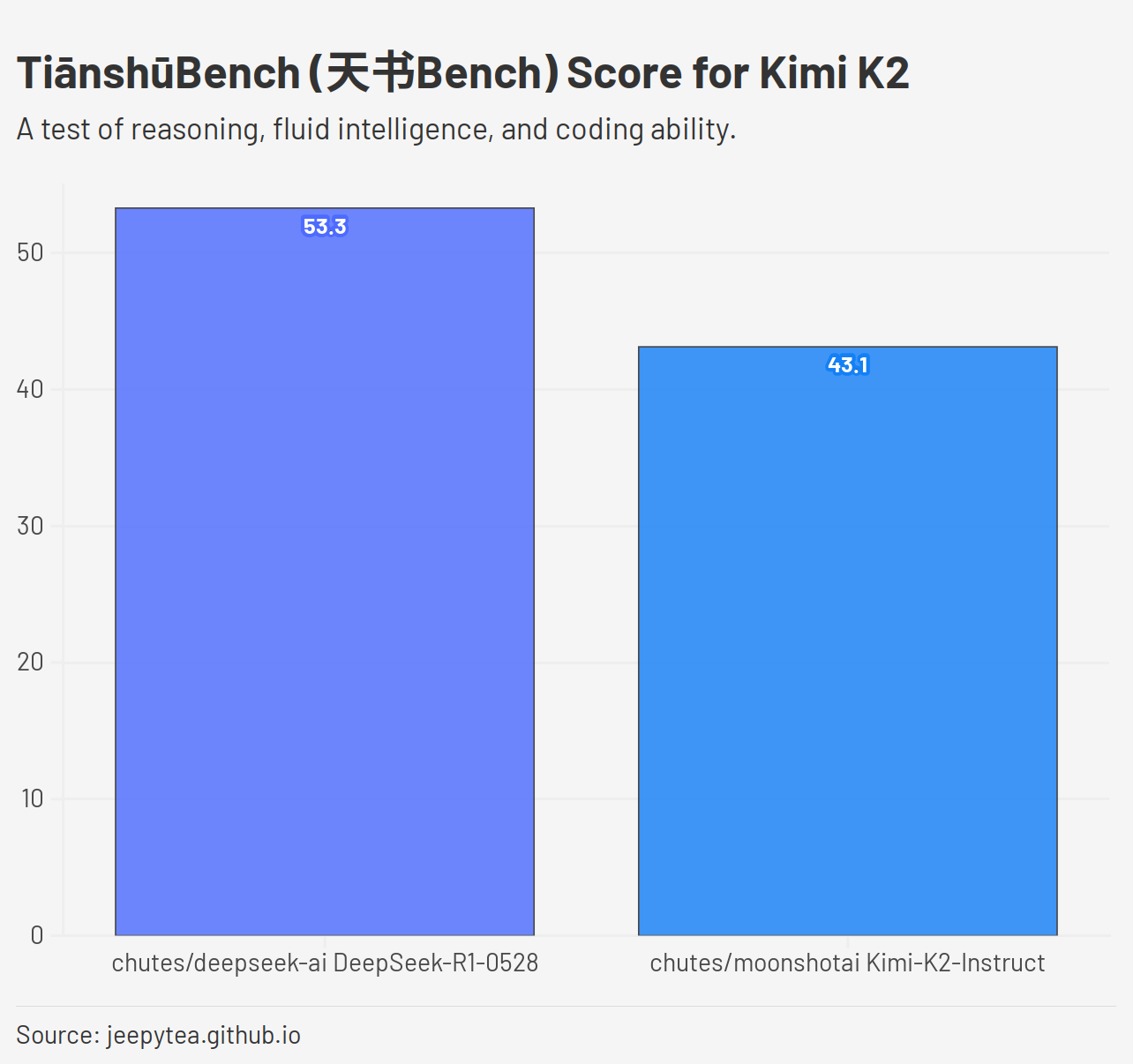
The Big Reveal: The Current TiānshūBench Champion!
Of the 3 tested models, DeepSeek-R1 comes out on top, with 47.34% of
test cases passed. The newer DeepSeek-R1-0528 is very close behind with
46.56% of test cases passed. Finally DeepSeek-V3-0324 falls behind these
two at 30.16%.
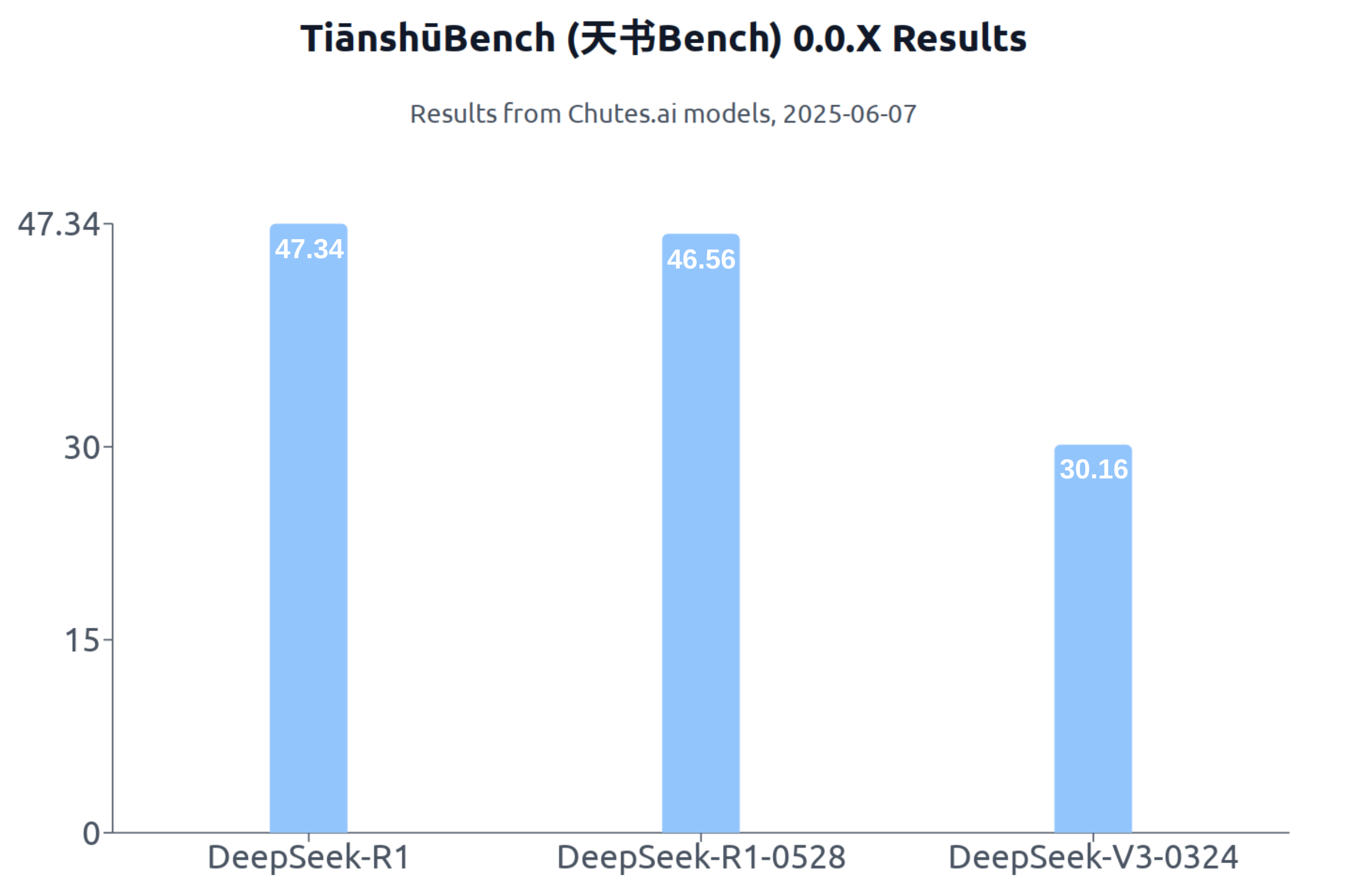
chutes/deepseek-ai/DeepSeek-R1: 303/640 (47.34%) passed
chutes/deepseek-ai/DeepSeek-R1-0528: 298/640 (46.56%) passed
chutes/deepseek-ai/DeepSeek-V3-0324: 193/640 (30.16%) passed
Wrapping Up
Of course, this research raises as many questions as it answers:
- How do other models compare with DeepSeek on TiānshūBench?
- Which models are the most efficient with regard to time and cost in
generating an answer?
- What do AI systems most commonly get confused about?
- How can we improve artificial intelligence planning and reasoning?
Solving some of these problems will require new additions to the
TiānshūBench code in the short term:
- Error code tags in Allure to distinguish different kinds of errors,
e.g. syntax errors and runtime errors.
- Shot and token count logging
- Calculating the number of correct answers per dollar spent. I
especially like this as a benchmark, because it can continue to grow
as inference gets cheaper, rather than being capped like percentage
of questions correct.
Questions and suggestions are welcome!